














 微短剧拍摄剪辑
微短剧拍摄剪辑  IP短视频
IP短视频 C/C++
C/C++ 狂野架构师
狂野架构师 AI应用与智能体开发
AI应用与智能体开发 AI大模型开发
AI大模型开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI测试
AI测试 AI运维
AI运维 AI视觉设计
AI视觉设计 AI视频与短剧创作
AI视频与短剧创作 跨境电商运营
跨境电商运营 AI鸿蒙开发
AI鸿蒙开发 AI大数据开发
AI大数据开发 C/C++
C/C++ 前端开发
前端开发 产品经理
产品经理 拍摄剪辑+短视频制作
拍摄剪辑+短视频制作 PMP项目管理认证
PMP项目管理认证 Go语言与区块链
Go语言与区块链 大数据
大数据 PHP工程师
PHP工程师 Android+物联网
Android+物联网 iOS
iOS .NET
.NET
1、原理篇
我们用人话而不是大段的数学公式来讲讲ALS是怎么一回事。
1.1 你听说过推荐算法么
假如我是豆瓣的CEO,很多豆瓣的用户在豆瓣电影上都会对电影进行评分。那么根据这个评分数据,我们有可能知道这些用户除了自己评过分的电影之外还喜欢或讨厌哪些电影吗?这就是一个典型的推荐问题,解决这一类问题的算法被称为推荐算法。
1.2 什么是协同过滤
协同过滤的英文全称是Collaborative Filtering,简称CF。注意,这不是一款游戏!从字面上分析,协同就是寻找共同点,过滤就是筛选出优质的内容。
1.3 协同过滤的分类
一般来说,协同过滤推荐分为三种类型:
基于用户(user-based)的协同过滤,通过计算用户和用户的相似度找到跟用户A相似的用户B, C, D...再把这些用户喜欢的内容推荐给A;
基于物品(item-based)的协同过滤,通过计算物品和物品的相似度找到跟物品1相似的物品2, 3, 4...再把这些物品推荐给看过物品1的用户们;
基于模型(model based)的协同过滤。主流的方法可以分为:矩阵分解,关联算法,聚类算法,分类算法,回归算法,神经网络。
1.4 矩阵分解
矩阵分解 (decomposition, factorization)是将矩阵拆解为数个矩阵的乘积。比如豆瓣电影有m个用户,n个电影。那么用户对电影的评分可以形成一个m行n列的矩阵R,我们可以找到一个m行k列的矩阵U,和一个k行n列的矩阵I,通过U * I来得到矩阵R。
1.5 ALS
如果想通过矩阵分解的方法实现基于模型的协同过滤,ALS是一个不错的选择,其英文全称是Alternating Least Square,翻译过来是交替最小二乘法。假设用户为a,物品为b,评分矩阵为R(m, n),可分解为用户矩阵U(k, m)和物品矩阵I(k, n),其中m, n, k代表矩阵的维度。前方小段数学公式低能预警:
根据矩阵分解的定义,有
![]()
1、用MSE作为损失函数,为了方便化简,加法符号左侧的常数改为-1/2
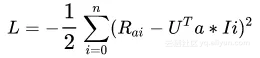
2、对损失函数求U_a的一阶偏导数,那
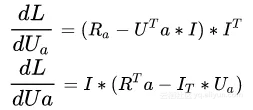
3、 令一阶偏导数等于0
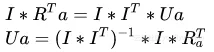
4、同理,可证
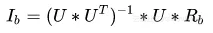
1.6 求解用户矩阵U和物品矩阵I
矩阵R是已知的,我们随机生成用户矩阵U,
1、利用1.5中的式5、R和U求出I
2、利用1.5中的式6、R和I求出U
如此交替地执行步骤1和步骤2,直到算法收敛或者迭代次数超过了最大限制,最终我们用RMSE来评价模型的好坏。
实现篇
本人用全宇宙最简单的编程语言——Python实现了ALS算法,没有依赖任何第三方库,便于学习和使用。
注:代码中用到的Matrix类是我写的一个矩阵类,可以取出矩阵的行或列,计算矩阵的乘法、转置和逆。
2.1 创建ALS类
初始化,存储用户ID、物品ID、用户ID与用户矩阵列号的对应关系、物品ID与物品矩阵列号的对应关系、用户已经看过哪些物品、评分矩阵的Shape以及RMSE。
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 | class ALS(object): def __init__(self): self.user_ids = None self.item_ids = None self.user_ids_dict = None self.item_ids_dict = None self.user_matrix = None self.item_matrix = None self.user_items = None self.shape = None self.rmse = None |
2.2 数据预处理
对训练数据进行处理,得到用户ID、物品ID、用户ID与用户矩阵列号的对应关系、物品ID与物品矩阵列号的对应关系、评分矩阵的Shape、评分矩阵及评分矩阵的转置。
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | def _process_data(self, X): self.user_ids = tuple((set(map(lambda x: x[0], X)))) self.user_ids_dict = dict(map(lambda x: x[::-1], enumerate(self.user_ids))) self.item_ids = tuple((set(map(lambda x: x[1], X)))) self.item_ids_dict = dict(map(lambda x: x[::-1], enumerate(self.item_ids))) self.shape = (len(self.user_ids), len(self.item_ids)) ratings = defaultdict(lambda: defaultdict(int)) ratings_T = defaultdict(lambda: defaultdict(int)) for row in X: user_id, item_id, rating = row ratings[user_id][item_id] = rating ratings_T[item_id][user_id] = rating err_msg = "Length of user_ids %d and ratings %d not match!" % ( len(self.user_ids), len(ratings)) assert len(self.user_ids) == len(ratings), err_msg err_msg = "Length of item_ids %d and ratings_T %d not match!" % ( len(self.item_ids), len(ratings_T)) assert len(self.item_ids) == len(ratings_T), err_msg return ratings, ratings_T |
2.3 用户矩阵乘以评分矩阵
实现稠密矩阵与稀疏矩阵的矩阵乘法,得到用户矩阵与评分矩阵的乘积。
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 12 | def _users_mul_ratings(self, users, ratings_T): def f(users_row, item_id): user_ids = iter(ratings_T[item_id].keys()) scores = iter(ratings_T[item_id].values()) col_nos = map(lambda x: self.user_ids_dict[x], user_ids) _users_row = map(lambda x: users_row[x], col_nos) return sum(a * b for a, b in zip(_users_row, scores)) ret = [[f(users_row, item_id) for item_id in self.item_ids] for users_row in users.data] return Matrix(ret) |
2.4 物品矩阵乘以评分矩阵
实现稠密矩阵与稀疏矩阵的矩阵乘法,得到物品矩阵与评分矩阵的乘积。
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 12 | def _items_mul_ratings(self, items, ratings): def f(items_row, user_id): item_ids = iter(ratings[user_id].keys()) scores = iter(ratings[user_id].values()) col_nos = map(lambda x: self.item_ids_dict[x], item_ids) _items_row = map(lambda x: items_row[x], col_nos) return sum(a * b for a, b in zip(_items_row, scores)) ret = [[f(items_row, user_id) for user_id in self.user_ids] for items_row in items.data] return Matrix(ret) |
2.5 生成随机矩阵
[Python] 纯文本查看 复制代码
1 2 3 | def _gen_random_matrix(self, n_rows, n_colums): data = [[random() for _ in range(n_colums)] for _ in range(n_rows)] return Matrix(data) |
2.6 计算RMSE
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 | def _get_rmse(self, ratings): m, n = self.shape mse = 0.0 n_elements = sum(map(len, ratings.values())) for i in range(m): for j in range(n): user_id = self.user_ids[i] item_id = self.item_ids[j] rating = ratings[user_id][item_id] if rating > 0: user_row = self.user_matrix.col(i).transpose item_col = self.item_matrix.col(j) rating_hat = user_row.mat_mul(item_col).data[0][0] square_error = (rating - rating_hat) ** 2 mse += square_error / n_elements return mse ** 0.5 |
2.7 训练模型
数据预处理
变量k合法性检查
生成随机矩阵U
交替计算矩阵U和矩阵I,并打印RMSE信息,直到迭代次数达到max_iter
保存最终的RMSE
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | def fit(self, X, k, max_iter=10): ratings, ratings_T = self._process_data(X) self.user_items = {k: set(v.keys()) for k, v in ratings.items()} m, n = self.shape error_msg = "Parameter k must be less than the rank of original matrix" assert k < min(m, n), error_msg self.user_matrix = self._gen_random_matrix(k, m) for i in range(max_iter): if i % 2: items = self.item_matrix self.user_matrix = self._items_mul_ratings( items.mat_mul(items.transpose).inverse.mat_mul(items), ratings ) else: users = self.user_matrix self.item_matrix = self._users_mul_ratings( users.mat_mul(users.transpose).inverse.mat_mul(users), ratings_T ) rmse = self._get_rmse(ratings) print("Iterations: %d, RMSE: %.6f" % (i + 1, rmse)) self.rmse = rmse |
2.8 预测一个用户
预测一个用户感兴趣的内容,剔除用户已看过的内容。然后按感兴趣分值排序,取出前n_items个内容。
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 | def _predict(self, user_id, n_items): users_col = self.user_matrix.col(self.user_ids_dict[user_id]) users_col = users_col.transpose items_col = enumerate(users_col.mat_mul(self.item_matrix).data[0]) items_scores = map(lambda x: (self.item_ids[x[0]], x[1]), items_col) viewed_items = self.user_items[user_id][b]2.9 预测多个用户[/b] 循环调用2.8,预测多个用户感兴趣的内容。[mw_shl_code=python,true]def predict(self, user_ids, n_items=10): return [self._predict(user_id, n_items) for user_id in user_ids] |
3 效果评估
3.1 main函数
使用电影评分数据集,训练模型并统计RMSE。
[Python] 纯文本查看 复制代码
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | @run_timedef main(): print("Tesing the accuracy of ALS...") X = load_movie_ratings() model = ALS() model.fit(X, k=3, max_iter=5) print() print("Showing the predictions of users...") user_ids = range(1, 5) predictions = model.predict(user_ids, n_items=2) for user_id, prediction in zip(user_ids, predictions): _prediction = [format_prediction(item_id, score) for item_id, score in prediction] print("User id:%d recommedation: %s" % (user_id, _prediction)) |
3.2 效果展示
设置k=3,迭代5次,并展示了前4个用户的推荐内容,最终RMSE为0.370,运行时间46.5秒,效果还算不错~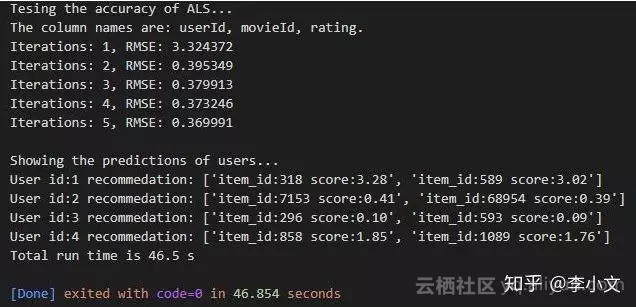








 苏公网安备32132202000574号
苏公网安备32132202000574号