














 微短剧拍摄剪辑
微短剧拍摄剪辑  IP短视频
IP短视频 C/C++
C/C++ 狂野架构师
狂野架构师 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 前端开发
前端开发 AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 C/C++
C/C++ 产品经理
产品经理 拍摄剪辑+短视频制作
拍摄剪辑+短视频制作 PMP项目管理认证
PMP项目管理认证 跨境电商
跨境电商 Go语言与区块链
Go语言与区块链 大数据
大数据 PHP工程师
PHP工程师 Android+物联网
Android+物联网 iOS
iOS .NET
.NET
· 回顾mybatis的操作的核心步骤
· 编写核心类SqlSessionFacotryBuild进行解析配置文件
· 深度分析解析SqlSessionFacotryBuild干的核心工作
· 编写核心类SqlSessionFacotry
· 深度分析解析SqlSessionFacotry干的核心工作
· 编写核心类SqlSession
· 深度分析解析SqlSession干的核心工作
· 总结自定义mybatis用的技术点
一. 回顾mybatis的操作的核心步骤
声明一点我们本篇主要探讨的是mybatis的注解方式的操作, 完全从头开始都是小编从头开搞的, 如果与其他大神的代码思维有出入请多指教
我们首先需要准备mybatis的核心配置文件(当然导入相关的坐标这里不在啰嗦)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--数据库连接信息-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql:///db6?useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<mappers>
<!-- 配置sql语句编写的位置 -->
<package name="cn.itcast.mapper"/>
</mappers>
</configuration>准备好结果的实体类以及在mapper接口上编写需要执行的sql语句
public class User {
private Integer uid;
private String username;
private String password;
private String nickname;
}package cn.itcast.mapper;
import cn.itcast.pojo.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper {
@Select("select * from users")
List<User> findAll();
}使用mybatis的api来帮助我们完成sql语句的执行以及结果集的封装
//1.关联主配置文件
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
//2.解析配置文件
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory sqlSessionFactory = builder.build(in);
//3.创建会话对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//4.可以采用接口代理的方式
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> all = mapper.findAll();
System.out.println(all);
//5.释放资源
sqlSession.close();思考: mybatis大致是如何帮我们完成相关操作的 ?
我们通过Resources的getResourceAsStream告诉了mybatis我们编写的核心配置文件的位置, mybatis就可以找到我们数据库的连接信息, 也同时找到我们编写的sql语句的地方, 然后可以将其解析按照某种规则存放起来, 我们通过调用接口代理的方式执行方法时, 可以找到对应方法上的sql语句然后执行将结果封装返回给我们
二. 编写核心类SqlSessionFacotryBuild进行解析配置文件
那么我们废话不多说开始我们自定义mybatis的旅程,
1.首先我们需要用户编写配置文件, 然后通过我们自己的Resources来告诉我们配置文件所在位置
package com.itheima.ibatis.configuration;
import java.io.InputStream;
public class Resources {
public static InputStream getResourceAsStream(String path) {
return ClassLoader.getSystemClassLoader().getResourceAsStream(path);
}
}
2. 然后需要定义SqlSessionFacotryBuild来对配置文件进行解析分发
package com.itheima.ibatis.configuration;
import com.itheima.ibatis.core.session.SqlSessionFactory;
import com.itheima.ibatis.core.session.impl.DefaultSqlSessionFactory;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import javax.sql.DataSource;
import java.io.File;
import java.io.InputStream;
import java.lang.reflect.Method;
import java.util.List;
import java.util.Properties;
public class SqlSessionFactoryBuilder {
private Configuration configuration = new Configuration();
public SqlSessionFactory build(InputStream in) {
SAXReader saxReader = new SAXReader();
Document document = null;
try {
document = saxReader.read(in);
} catch (DocumentException e) {
e.printStackTrace();
}
Element rootElement = document.getRootElement();
parseEnvironment(rootElement.element("environments"));
parseMapper(rootElement.element("mappers"));
return new DefaultSqlSessionFactory(configuration);
}
private void parseMapper(Element mapper) {
String pack = mapper.element("package").attributeValue("name");
String directory = pack.replace(".", "/");
String path = ClassLoader.getSystemClassLoader().getResource("").getPath();
File mapperDir = new File(path, directory);
if (!mapperDir.exists()) {
throw new RuntimeException("找不到mapper映射");
}
findMapper(mapperDir, pack);
// System.out.println(configuration.getSql());
}
private void findMapper(File mapperDir, String base) {
File[] files = mapperDir.listFiles();
if (files != null) {
for (File file : files) {
if (file.isFile()) {
if (file.getName().endsWith(".class")) {
String name = file.getName();
name = name.substring(0, name.lastIndexOf("."));
String className = base + "." + name;
initMapper(className);
}
} else {
findMapper(file, base + "." + file.getName());
}
}
}
}
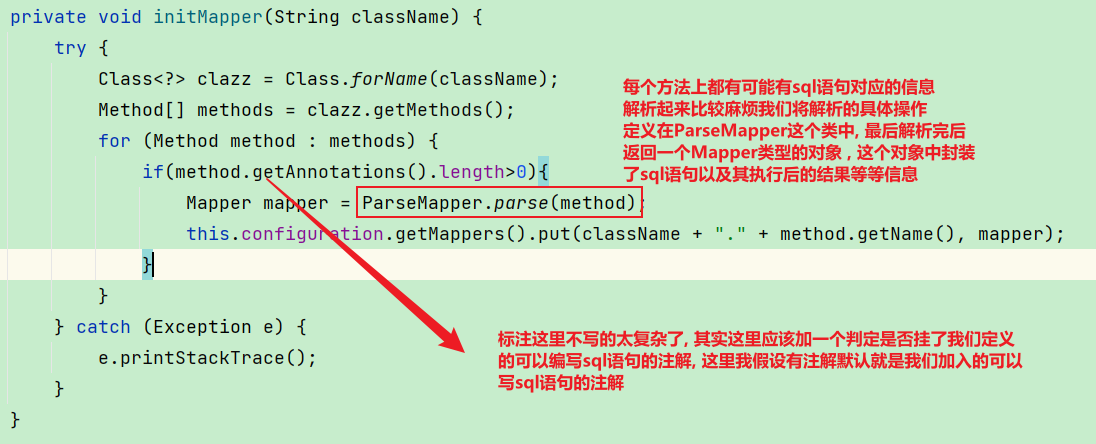
private void initMapper(String className) {
try {
Class<?> clazz = Class.forName(className);
Method[] methods = clazz.getMethods();
for (Method method : methods) {
if(method.getAnnotations().length>0){
Mapper mapper = ParseMapper.parse(method);
this.configuration.getMappers().put(className + "." + method.getName(), mapper);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
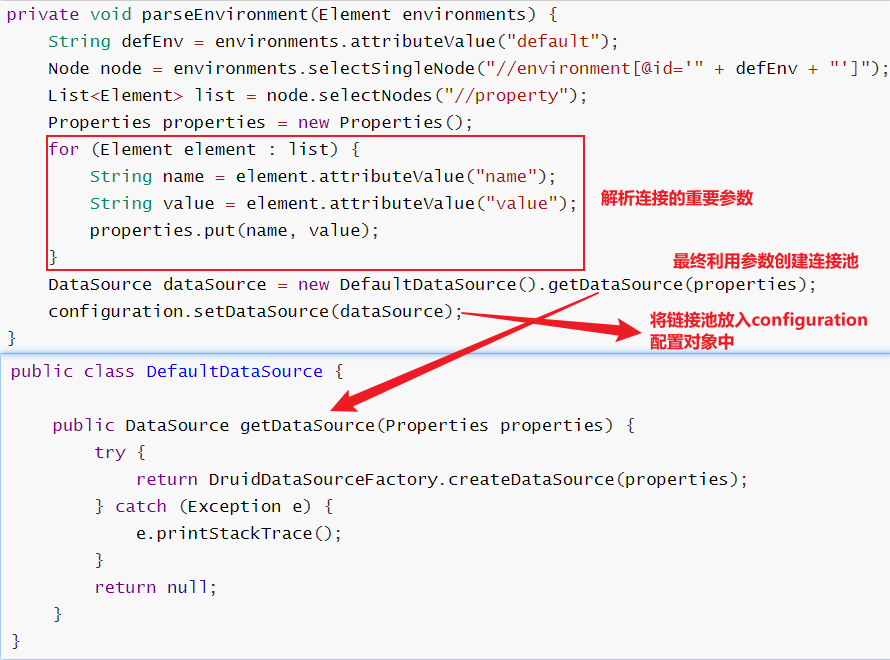
private void parseEnvironment(Element environments) {
String defEnv = environments.attributeValue("default");
Node node = environments.selectSingleNode("//environment[@id='" + defEnv + "']");
List<Element> list = node.selectNodes("//property");
Properties properties = new Properties();
for (Element element : list) {
String name = element.attributeValue("name");
String value = element.attributeValue("value");
properties.put(name, value);
}
DataSource dataSource = new DefaultDataSource().getDataSource(properties);
configuration.setDataSource(dataSource);
}
}
三. 深度分析解析SqlSessionFacotryBuild干的核心工作
1. build(InputStream in) 方法做的工作
①借助Dom4j的来解析了xml文件, 将environments解析工作分发给了parseEnvironment(Element environments)
②将mappers的解析工作分发给了parseMapper(Element mapper)
2. parseEnvironment(Element environments)方法做的工作
①主要解析了连接数据库的参数们, 并且创建了数据库连接池
自定义连接池非本章节的重点,所以这里内部本质采用的Druid连接池来做了简化
package com.itheima.ibatis.configuration;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.util.Properties;
public class DefaultDataSource {
public DataSource getDataSource(Properties properties) {
try {
return DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}②将解析好的连接池放入configuration对象中,mappers成员变量先别纠结下一章节会讲解
package com.itheima.ibatis.configuration;
import lombok.Data;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Data
public class Configuration {
private Map<String, Mapper> mappers = new HashMap<>();
private DataSource dataSource;
}详细图解如下图
3.parseMapper(Element mapper) 方法做的工作
①解析出用户配置的package找到sql语句所在接口的文件夹, 交给initMapper来处理

②递归找到这个包下所有的.class文件,并且获取到接口的全类名, 然后交给initMapper来处理

③initMapper通过反射获取类中的每一个方法,将方法交给一个专门解析方法上的注解的工具类ParseMapper的parse方法处理,处理完后将其放到configuration中的mappers的集合中
④ParseMapper的parse方法做的工作, 这是解析配置的核心地方
package com.itheima.ibatis.configuration;
import java.lang.annotation.Annotation;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
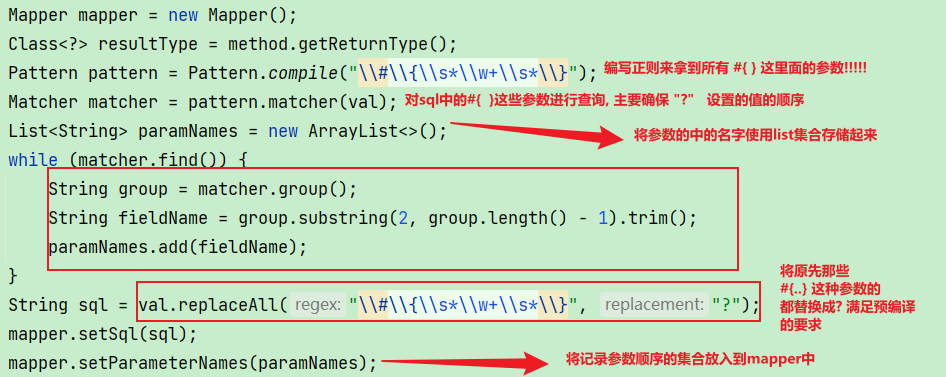
public class ParseMapper {
public static Mapper parse(Method method) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
Annotation[] annotations = method.getAnnotations();
Object value = annotations[0].getClass().getMethod("value").invoke(annotations[0]);
Mapper mapper = new Mapper();
Class<?> resultType = method.getReturnType();
String val = (String) value;
Pattern pattern = Pattern.compile("\#\{\s*\w+\s*\}");
Matcher matcher = pattern.matcher(val);
List<String> paramNames = new ArrayList<>();
while (matcher.find()) {
String group = matcher.group();
String fieldName = group.substring(2, group.length() - 1).trim();
paramNames.add(fieldName);
}
String sql = val.replaceAll("\#\{\s*\w+\s*\}", "?");
mapper.setSql(sql);
mapper.setParameterNames(paramNames);
mapper.setSql(sql);
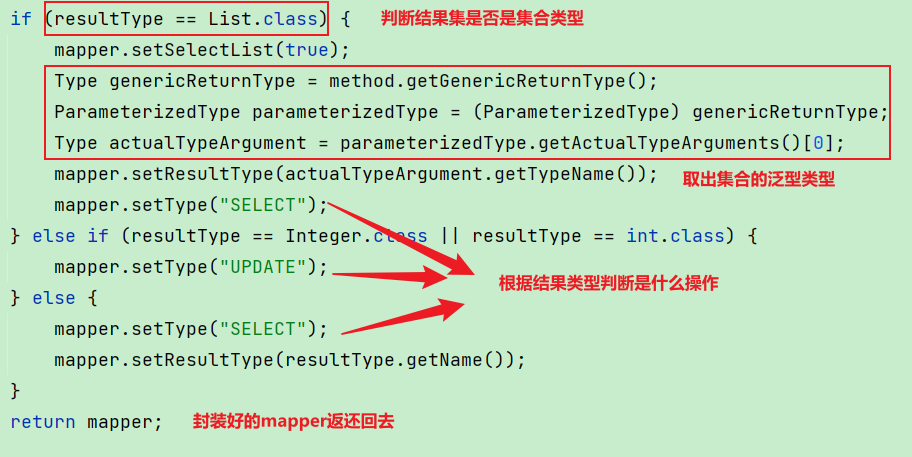
if (resultType == List.class) {
mapper.setSelectList(true);
Type genericReturnType = method.getGenericReturnType();
ParameterizedType parameterizedType = (ParameterizedType) genericReturnType;
Type actualTypeArgument = parameterizedType.getActualTypeArguments()[0];
mapper.setResultType(actualTypeArgument.getTypeName());
mapper.setType("SELECT");
} else if (resultType == Integer.class || resultType == int.class) {
mapper.setType("UPDATE");
} else {
mapper.setType("SELECT");
mapper.setResultType(resultType.getName());
}
return mapper;
}
}
首先拿到方法上的注解,得到用户填入的sql语句

然后处理sql语句#{参数}的这些数据, 然后将参数的顺序保存起来, 用来后期设置参数的数据做准备, 一个方法对应一个Mapper对象
然后再根据结果类型, 判断是什么类型相关的操作,方便后期执行对应的sql语句
四. 编写核心类SqlSessionFacotry
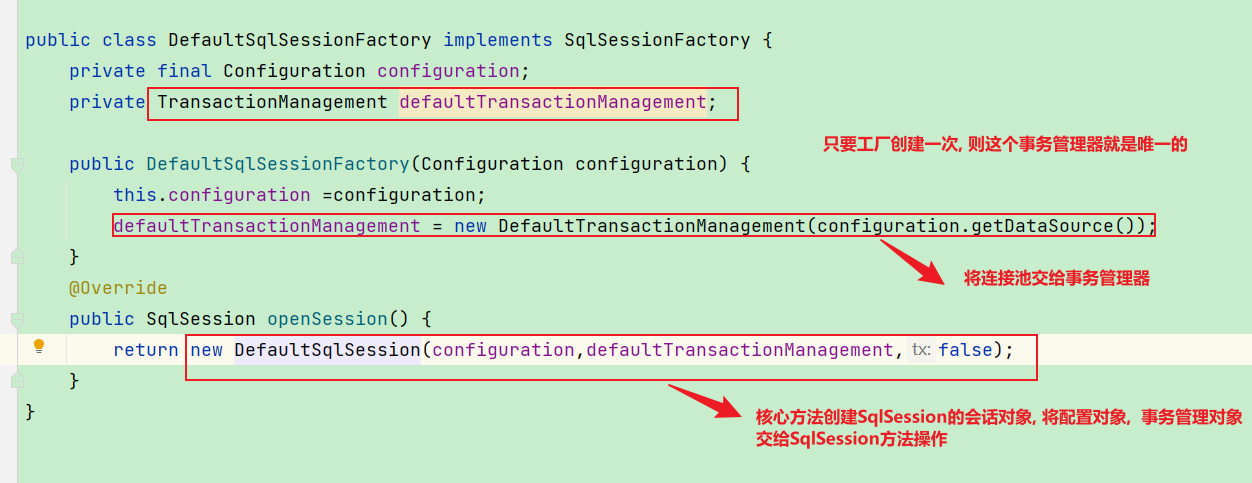
1.回顾那个地方创建的SqlSessionFacotry对象
经过SqlSessionFacotryBuilder的努力, 我们成功的将配置文件中核心的信息解析出来并放入了configuration对象中了, 然后我们此时将解析好的configuration传入到SqlSessionFacotry中

SqlSessionFactory的实现类如下:
public class DefaultSqlSessionFactory implements SqlSessionFactory {
private final Configuration configuration;
private TransactionManagement defaultTransactionManagement;
public DefaultSqlSessionFactory(Configuration configuration) {
this.configuration =configuration;
defaultTransactionManagement = new DefaultTransactionManagement(configuration.getDataSource());
}
@Override
public SqlSession openSession() {
return new DefaultSqlSession(configuration,defaultTransactionManagement,false);
}
}2.添加事务管理器
事务管理是一个小的功能, 里面希望使用ThreadLocal集合来保证一个用户拿到的链接是同一个
事务管理的代码如下:
public class DefaultTransactionManagement implements TransactionManagement {
private ThreadLocal<Connection> threadLocal = new ThreadLocal<>();
private DataSource dataSource;
public DefaultTransactionManagement(DataSource dataSource) {
this.dataSource = dataSource;
}
public Connection getConnection() {
Connection connection = threadLocal.get();
if (connection == null) {
try {
connection = dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
threadLocal.set(connection);
}
return connection;
}
@Override
public void commit() {
Connection connection = threadLocal.get();
if (connection != null ) {
try {
connection.commit();
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Override
public void rollback() {
Connection connection = threadLocal.get();
if (connection != null) {
try {
connection.rollback();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
public void close() {
Connection connection = threadLocal.get();
if (connection != null) {
try {
connection.close();
threadLocal.remove();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
@Override
public void begin() {
Connection connection = threadLocal.get();
if (connection != null) {
try {
connection.setAutoCommit(false);
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}五. 深度分析解析SqlSessionFacotry干的核心工作
1. SqlSession openSession() 方法做的工作
可以看的出来我们在这个方法创建了DefaultSqlSession对象,并传入封装好的configuration,默认的事务管理器
默认通过openSession事务是开启的等等相关的参数

六.编写核心类SqlSession
其实有SqlSession的接口,我们使用的实现类是DefaultSession, 这里记录了解析的配置对象configuration
默认事务管理器对象transactionManagement, 默认事务开启的状态tx标记
package com.itheima.ibatis.core.session.impl;
import com.itheima.ibatis.configuration.Configuration;
import com.itheima.ibatis.configuration.Mapper;
import com.itheima.ibatis.core.BaseExecutor;
import com.itheima.ibatis.core.annotation.Param;
import com.itheima.ibatis.core.session.SqlSession;
import com.itheima.ibatis.core.transaction.TransactionManagement;
import java.lang.reflect.*;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class DefaultSqlSession implements SqlSession {
private final Configuration configuration;
private final boolean tx;
private TransactionManagement transactionManagement;
public DefaultSqlSession(Configuration configuration, TransactionManagement transactionManagement, boolean tx) {
this.configuration = configuration;
this.transactionManagement = transactionManagement;
this.tx = tx;
}
public void close() {
transactionManagement.close();
}
@Override
public void commit() {
transactionManagement.commit();
}
@Override
public void rollback() {
transactionManagement.rollback();
}
@Override
public <T> List<T> selectList(String sqlId) {
return selectList(sqlId, null);
}
@Override
public <T> List<T> selectList(String sqlId, Object param) {
List<Object> list = new BaseExecutor(transactionManagement, tx).queryList(getMapper(sqlId), param);
return (List<T>) list;
}
@Override
public <T> T selectOne(String sqlId) {
return selectOne(sqlId, null);
}
@Override
public <T> T selectOne(String sqlId, Object param) {
return new BaseExecutor(transactionManagement, tx).query(getMapper(sqlId), param);
}
@Override
public int delete(String sqlId) {
return update0(sqlId, null);
}
@Override
public int delete(String sqlId, Object param) {
return update0(sqlId, param);
}
@Override
public int update(String sqlId) {
return update0(sqlId, null);
}
@Override
public int update(String sqlId, Object param) {
return update0(sqlId, param);
}
@Override
public int insert(String sqlId) {
return update0(sqlId, null);
}
@Override
public int insert(String sqlId, Object param) {
return update0(sqlId, param);
}
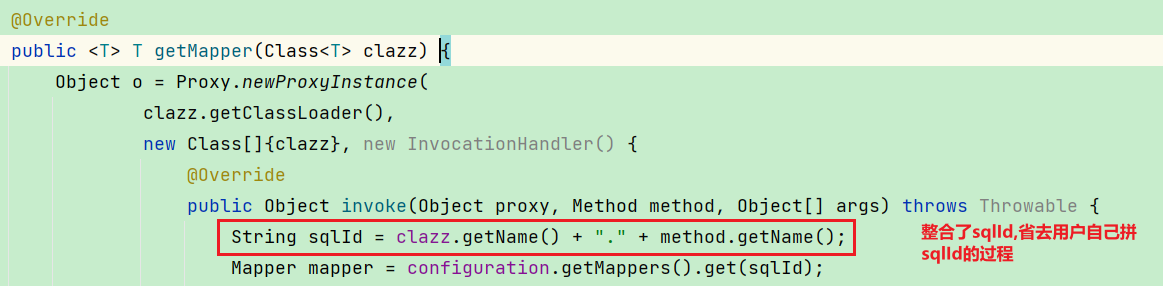
@Override
public <T> T getMapper(Class<T> clazz) {
Object o = Proxy.newProxyInstance(
clazz.getClassLoader(),
new Class[]{clazz}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String sqlId = clazz.getName() + "." + method.getName();
Mapper mapper = configuration.getMappers().get(sqlId);
String type = mapper.getType();
Object findParam = null;
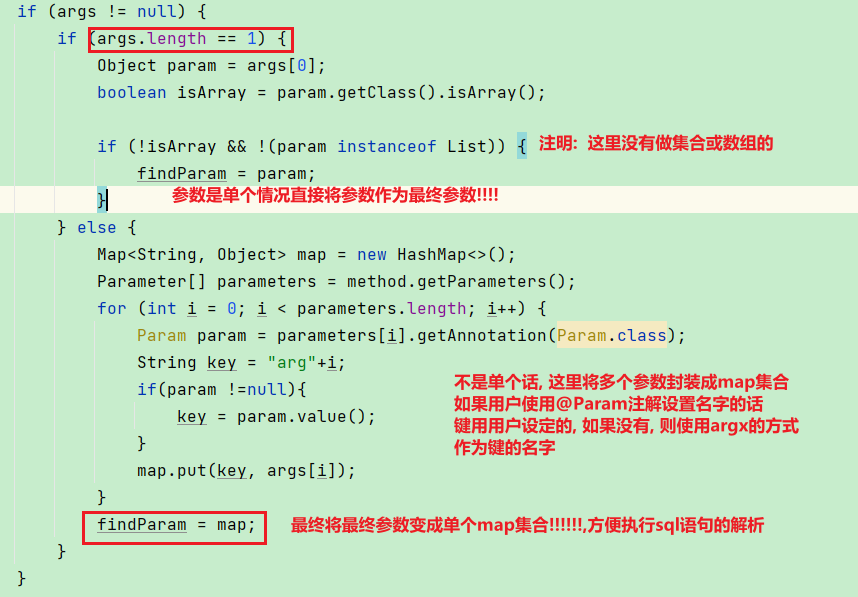
if (args != null) {
if (args.length == 1) {
Object param = args[0];
boolean isArray = param.getClass().isArray();
if (!isArray) {
findParam = param;
}
} else {
Map<String, Object> map = new HashMap<>();
Parameter[] parameters = method.getParameters();
for (int i = 0; i < parameters.length; i++) {
Param param = parameters[i].getAnnotation(Param.class);
String key = "arg"+i;
if(param !=null){
key = param.value();
}
map.put(key, args[i]);
}
findParam = map;
}
}
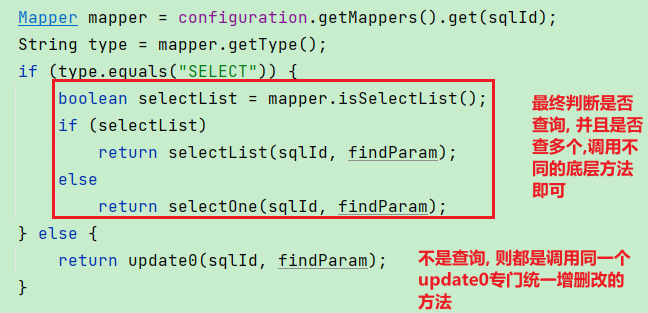
if (type.equals("SELECT")) {
boolean selectList = mapper.isSelectList();
if (selectList)
return selectList(sqlId, findParam);
else
return selectOne(sqlId, findParam);
} else {
return update0(sqlId, findParam);
}
}
});
return (T) o;
}
private int update0(String sqlId, Object param) {
return new BaseExecutor(transactionManagement, tx).update(getMapper(sqlId), param);
}
public Mapper getMapper(String sqlId) {
Mapper mapper = configuration.getMappers().get(sqlId);
if (mapper == null) {
throw new RuntimeException("没有找到sql映射,请检查");
}
return mapper;
}
}七.深度分析解析SqlSession干的核心工作
1.selectOne & selectList做的工作
主要是分发了下功能, 执行sql语句避免不了有参数和无参数的, 都让调用有参数的方便管理

在执行前, 考虑还有一种情况, 用户不是通过接口代理的方式来执行以上方法, 这样手动输入sqlId容易造成错误
这里做一个健壮性判断

BaseExecutor中的query以及queryList做的核心工作
首先这两个方法的特点都是查询, 其步骤基本类似, 所以这里可以合并一起转调query0功能

这里需要对参数进行设定, 还根据最后isOne的参数决定返回值是否是单个

参数设置这里比较复杂我们通过图解的方式来解释, (注: 参数是List集合类型的和数组类型的没有做!!!)

对结果的封装主要用到内省技术和数据库元数据等等知识点
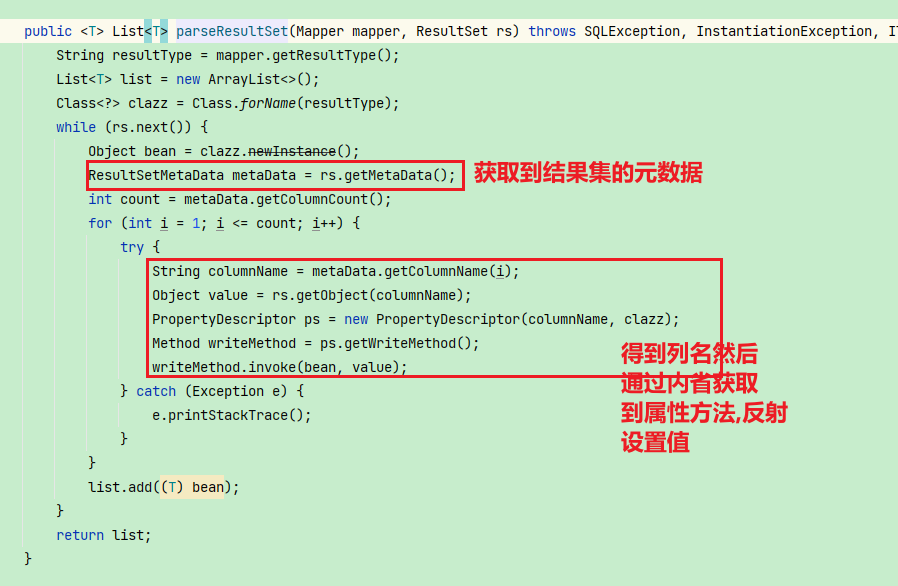
2.update&delete&insert做的工作
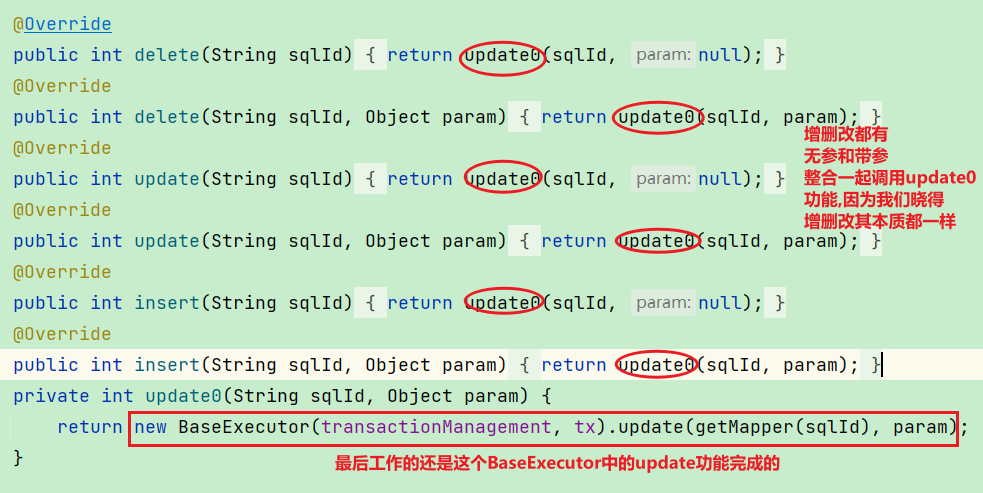
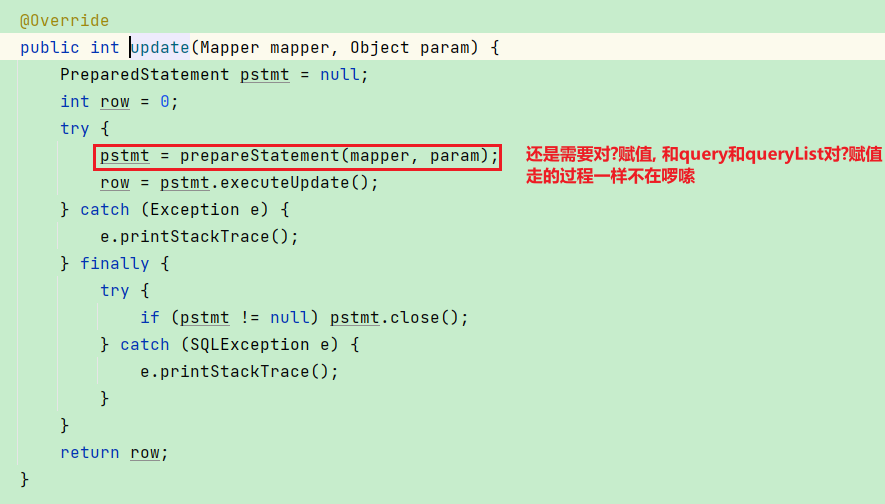
BaseExecutor中的update做的核心工作
还是和query&queryList一样需要设置参数, 不管是增删改其本质其结果都是一致
3.getMapper代理模式开发的原理
主要使用的动态代理的技术创建接口的实现类, 内部主要整合了sqlId和参数, 省去用户自己拼sqlId拼错的风险
也同时解决用户手动合参数的麻烦, 但是最终工作的还是selectOne,selectList以及update0这些方法
总结自定义mybatis用的技术点
一款框架的诞生肯定不是一蹴而就的, 随着时间慢慢推进逐步更新出来, 所以一款好的框架肯定要经过
很多考验才能够稳定靠谱, 但是纵观整篇用的技术点, 不难发现框架也是由基础代码编写而来,解决大量重复
的工作, 提供扩展性等等机制,比如本篇用核心的技术点有
① 反射
② 内省
③ 解析xml
④ 动态代理
⑤ 工厂设计模式








 苏公网安备32132202000574号
苏公网安备32132202000574号