














 微短剧拍摄剪辑
微短剧拍摄剪辑  IP短视频
IP短视频 C/C++
C/C++ 狂野架构师
狂野架构师 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 前端开发
前端开发 AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 C/C++
C/C++ 产品经理
产品经理 拍摄剪辑+短视频制作
拍摄剪辑+短视频制作 PMP项目管理认证
PMP项目管理认证 跨境电商
跨境电商 Go语言与区块链
Go语言与区块链 大数据
大数据 PHP工程师
PHP工程师 Android+物联网
Android+物联网 iOS
iOS .NET
.NET
1. 为什么我们需要自定义分词器
1.1 安装拼音分词器
要实现拼音分词检索,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。
地址:https://github.com/medcl/elasticsearch-analysis-pinyin
把yinpin分词器拷贝到es的/plugins目录里面
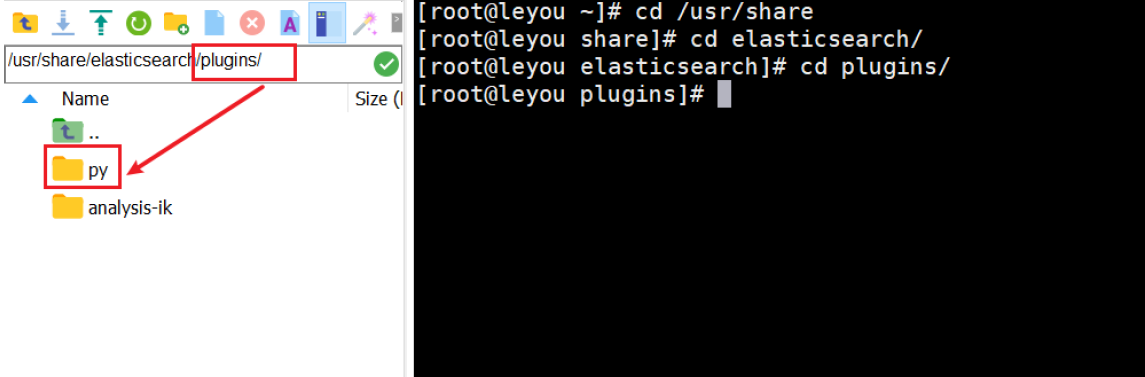
重启es的容器:
docker restart elasticsearch测试拼音分词器是否起作用:

结果
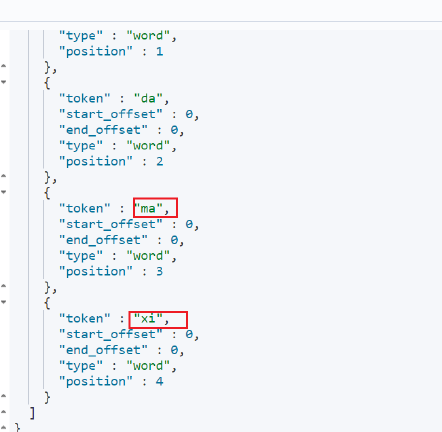
拼音分词器对我们每一个汉字都解析出对应的中文,但是这个并不是我们所需要的结果,我们需要的结果基于ik分词器的基础上的拼音,比如: 长隆大马戏可以分词出马戏, 那么就应该有对应的拼音——maxi。 如果我们需要实现该效果我们则需要自定义分词器
2. 自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
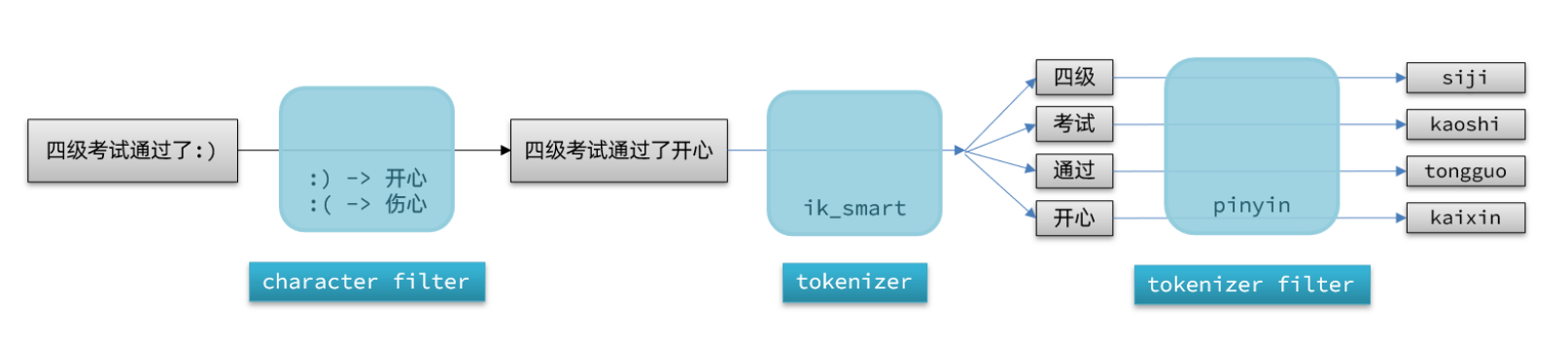
elasticsearch中分词器(analyzer)的组成包含三部分:
1、character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
2、tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
3、tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
声明自定义分词器的语法如下: 自定义分词器是属于某一个索引库的,并不是全局的, 代码里面创建的是my_analyzer自定义分词器,该分词器会先经过ik_max_word,然后经过过滤器,过滤器是拼音分词器,拼音分词器设置了一系列的参数:参数说明:
· keep_full_pinyin 启用此选项时,例如: 刘德华> [ liu , de , hua ],默认值:true
· keep_joined_full_pinyin 启用此选项时,例如: 刘德华> [ liudehua ],默认值:false
· keep_original 启用此选项时,也将保留原始输入,默认值:false
· limit_first_letter_length 设置 first_letter 结果的最大长度,默认值:16
· remove_duplicated_term 启用此选项时,将删除重复的术语以保存索引,例如: de的> de ,默认:false,注意:位置相关的查询可能会受到影响
· none_chinese_pinyin_tokenize 如果是拼音,则将非中文字母分成单独的拼音词,默认:
· true,例如: liudehuaalibaba13zhuanghan -> liu , de , hua , a , li , ba , ba , 13 , zhuang ,han , 注意: keep_none_chinese 并且keep_none_chinese_together 应该首先启用

结果









 苏公网安备32132202000574号
苏公网安备32132202000574号