














 微短剧拍摄剪辑
微短剧拍摄剪辑  IP短视频
IP短视频 C/C++
C/C++ 狂野架构师
狂野架构师 AI应用与智能体开发
AI应用与智能体开发 AI大模型开发
AI大模型开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI测试
AI测试 AI运维
AI运维 AI视觉设计
AI视觉设计 AI视频与短剧创作
AI视频与短剧创作 跨境电商运营
跨境电商运营 AI鸿蒙开发
AI鸿蒙开发 AI大数据开发
AI大数据开发 C/C++
C/C++ 前端开发
前端开发 产品经理
产品经理 拍摄剪辑+短视频制作
拍摄剪辑+短视频制作 PMP项目管理认证
PMP项目管理认证 Go语言与区块链
Go语言与区块链 大数据
大数据 PHP工程师
PHP工程师 Android+物联网
Android+物联网 iOS
iOS .NET
.NET
背景
笔者以前在电商公司,我们需要在8月18号做大促活动,我们会提前一天给所有的用户推送活动信息,且需要根据用户画像生成不同的推送内容。
当时我们总共有80万用户左右。
经测试,通过Spring Task和分布式锁,单台机器同时开启5个线程,执行时间需要27个小时左右,即便开10个线程,需要14个小时左右,显然执行时间过长。
解决方案
当时个推服务部署节点有3台,在每年大促期间可动态扩容,其余的机器资源没有充分利用起来。
要想短时间内完成推送,那么就得想办法让每台机器各自分一部分用户数据去执行,这样效率可提高原来的N倍。
那么就需要分布式任务去执行,核心思想如下图:
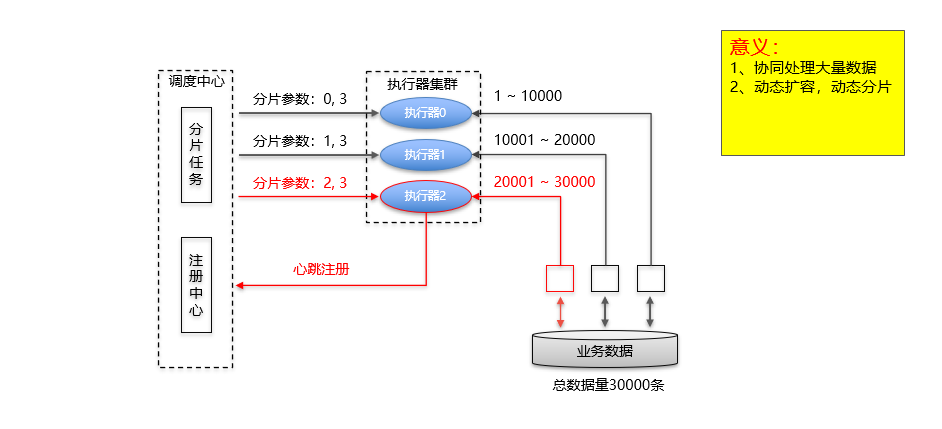
经过调研现有的开源的分布式任务调度框架,决定在elastic-job和xxl-job中选一个
Elastic Job是当当网开源一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成;定位为轻量级无中心化解决方案,使用 jar 包的形式提供分布式任务的协调服务。支持分布式调度协调、弹性扩容缩容、失效转移、错过执行作业重触发、并行调度、自诊断和修复等等功能特性。
XXL-Job官网是大众点评发布的分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
更倾向于选择XXL-JOB:
1、轻量级,支持通过Web页面对任务进行动态CRUD操作,操作简单
2、只依赖数据库作为集群注册中心,接入开发简单,不需要ZK
3、高可用、解耦、高性能、监控报警、分片、重试、故障转移
4、团队持续开发,社区活跃
5、支持后台直接查看每个任务执行实时日志
具体实现
在项目中集成xxl-job客户端
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.2.0</version>
</dependency>在配置文件中配置xxl-job信息
xxl:
job:
accessToken:
admin:
addresses: http://xxl部署IP地址:8080/xxl-job-admin
executor:
appname: vm-service
address:
ip:
port: 9989
logretentiondays: 30新增XxlJobConfig.java
package com.itheima.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
@Slf4j
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
// @Value("${xxl.job.executor.logpath}")
// private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
//xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}在xxl-job中新增执行器
注册方式选自动注册,这样方便动态扩容
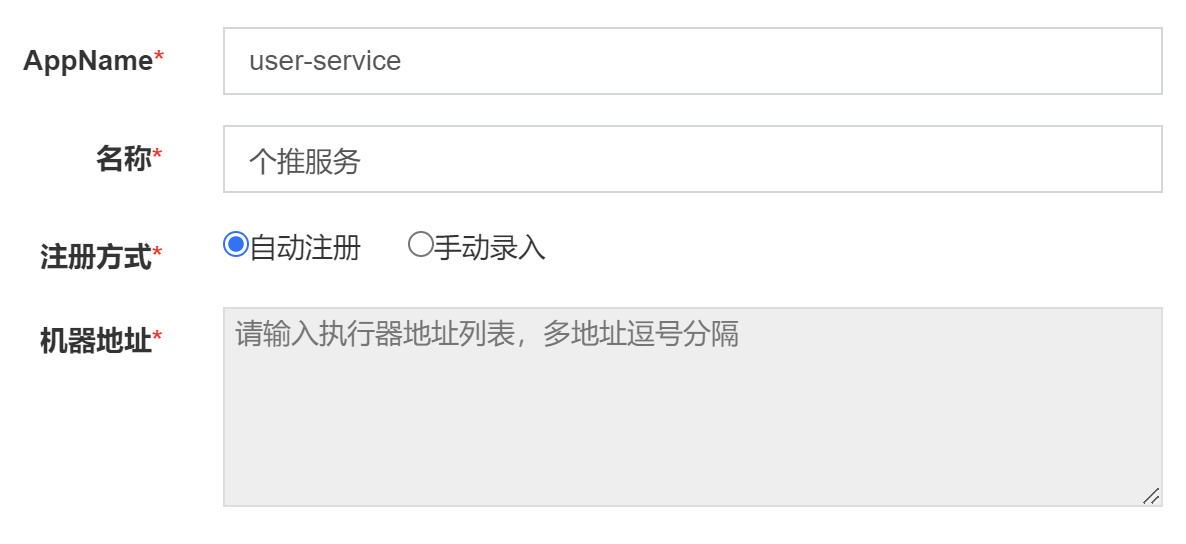
创建任务
路由策略选择分片广播

代码部分
在任务代码获取推送用户时,根据当前的分片及分片总数对用户ID取余,这样我们就可以在每个分片节点,获取不一样的数据。id值越连续,分片则越均匀。
ShardingUtil.ShardingVO shardingVo = ShardingUtil.getShardingVo();
int numbers = shardingVo.getTotal(); //分片总数
int index = shardingVo.getIndex(); //当前分片索引假设分片总数为3,当前节点获取到的分片索引为0,那么查询推送用户SQL如下:
SELECT user_id FROM `user_info` WHERE MOD(user_id,3)=0 注意:我们在实际代码中,分片总数和当前分片索引是以参数的形式传给查询的SQL语句的。
如上,即可完成分布式任务。
总结
在某些定时任务需要处理大量数据的情况下,我们可以通过引入分布式任务框架xxl-job,充分利用机器资源,将需要处理的数据均匀的分配到不同的机器上去执行,提高任务执行效率。








 苏公网安备32132202000574号
苏公网安备32132202000574号